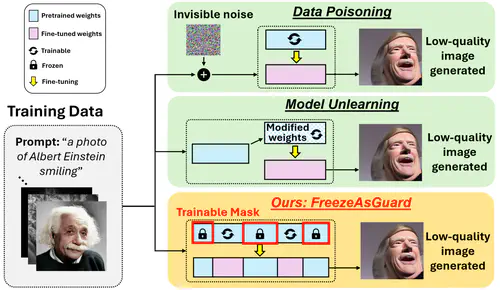
Illegally using fine-tuned diffusion models to forge human portraits has been a major threat to trustworthy AI. While most existing work focuses on detection of the AI-forged contents, our recent work instead aims to mitigate such illegal domain adaptation by applying safeguards on diffusion models. Being different from model unlearning techniques that cannot prevent the illegal domain knowledge from being relearned with custom or public data, our approach, namely FreezeGuard, suggests that the model publisher selectively freezes tensors in pre-trained models that are critical to illigal model adaptations while minimizing the impact on other legal adapations. Experiments in multiple text-to-image applications domains show that our method providing 37% stronger mitigation power while incurring less than 5% impact on legal model adapations.