Reasoning Path and Latent State Analysis for Multi-view Visual Spatial Reasoning: A Cognitive Science Perspective
Abstract
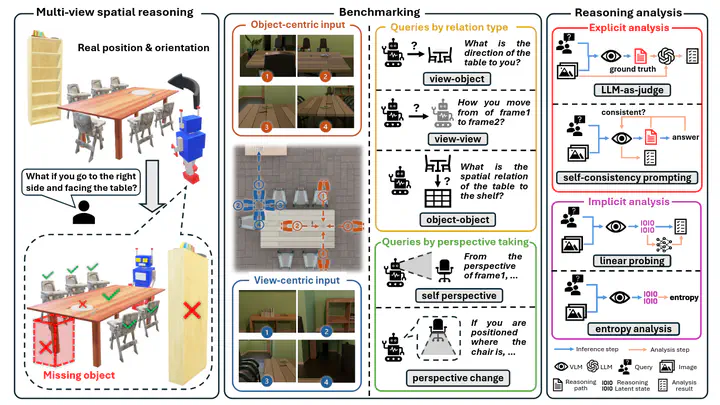
Spatial reasoning is a core aspect of human intelligence that allows perception, inference and planning in 3D environments. However, current vision-language models (VLMs) struggle to maintain geometric coherence and cross-view consistency for spatial reasoning in multi-view settings. We attribute this gap to the lack of fine-grained benchmarks that isolate multi-view reasoning from single-view perception and temporal factors. To address this, we present ReMindView-Bench, a cognitively grounded benchmark for evaluating how VLMs construct, align and maintain spatial mental models across complementary viewpoints. ReMindView-Bench systematically varies viewpoint spatial pattern and query type to probe key factors of spatial cognition. Evaluations of 15 current VLMs reveals consistent failures in cross-view alignment and perspective-taking in multi-view spatial reasoning, motivating deeper analysis on the reasoning process. Explicit phase-wise analysis using LLM-as-a-judge and self-consistency prompting shows that VLMs perform well on in-frame perception but degrade sharply when integrating information across views. Implicit analysis, including linear probing and entropy dynamics, further show progressive loss of task-relevant information and uncertainty separation between correct and incorrect trajectories. These results provide a cognitively grounded diagnosis of VLM spatial reasoning and reveal how multi-view spatial mental models are formed, degraded and destabilized across reasoning phases.
Benchmark
ReMindView-Bench consists of more than 50,000 multi-choice VQA pairs derived from 100 procedurally generated indoor scenes, and is constructed through a fully automated and physically grounded pipeline. It provides a fine-grained collection of VQA tasks from various cognitive science perspectives, as shown in the Figure below.
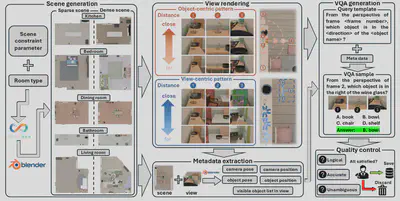
The pipeline first generates diverse indoor scenes with various room types and object densities by adjusting scene constraint parameters in Infinigen. Next, multiple views are rendered in Blender with controlled camera–object distances and spatial patterns. VQA data is produced using predefined query templates, combined with metadata extracted from the scene and views.
VLM Performance Evaluation
We evaluated current VLMs’ performance on multi-view spatial reasoning, using ReMindView-Bench benchmark. Our evaluations reveal a pronounced gap between human spatial reasoning and current VLMs’ capabilities:
- Object-centric reasoning remains easier than view-centric reasoning.
- Viewpoint transformations amplify the reasoning instability.
- Cross-frame reasoning is more challenging than within-frame reasoning.
- Number of objects and object-viewpoint distance jointly constrain spatial reasoning.
VLM Reasoning Analysis
Explicit analysis examines the correctness of a VLM’s reasoning phases and the consistency between reasoning and decision, pinpointing where spatial reasoning succeeds or breaks across reasoning phases. This includes LLMs-as-a-judge and Self-Consistency Prompting.
Implicit analysis complements the explicit analysis, by probing the latent representation of VLMs, such as entropy distribution and representation pattern. While explicit analysis measures what the VLM claims to reason, implicit analysis reveals how its internal representations evolve and where it deteriorates across reasoning phases. This includes Linear Probing Analysis and Entropy Dynamics Analysis.
Conclusion
Our work presents ReMindView-Bench, a cognitively grounded benchmark for evaluating spatial reasoning in multi-view settings. By combining explicit reasoning path analysis with implicit representation probing, we uncover fine-grained mechanisms explaining where and how current VLMs diverge from human-like spatial cognition. Comprehensive analysis shows that VLM limitations primarily stem from insufficient cross-view geometric alignment, unstable inference progression, and weak confidence calibration across reasoning phases. These findings highlight the need for VLM to maintain coherent spatial representations cross views, calibrate uncertainty dynamically, and integrate explicit and implicit signals to achieve cognitively grounded spatial reasoning.
Associated Dataset
We also published the associated dataset together with this paper.
