PhyT2V: LLM-Guided Iterative Self-Refinement for Physics-Grounded Text-to-Video Generation
Abstract
Text-to-video (T2V) generation has been recently enabled by transformer-based diffusion models, but current T2V models lack capabilities in adhering to the real-world common knowledge and physical rules, due to their limited understanding of physical realism and deficiency in temporal modeling. Existing solutions are either data-driven or require extra model inputs, but cannot be generalizable to out-of-distribution domains. In this paper, we present PhyT2V, a new data-independent T2V technique that expands the current T2V model’s capability of video generation to out-of-distribution domains, by enabling chain-of-thought and step-back reasoning in T2V prompting. Our experiments show that PhyT2V improves existing T2V models’ adherence to real-world physical rules by 2.3x, and achieves 35% improvement compared to T2V prompt enhancers.
Overview
Text-to-video (T2V) generation with transformer-based diffusion model can produce videos conditioned on textual prompts. These models demonstrate astonishing capabilities of generating complex and photorealistic scenes, but still have significant drawbacks in adhering to the real-world common knowledge and physical rules, such as quantity, material, fluid dynamics, gravity, motion, collision and causality, and such limitations fundamentally prevent current T2V models from being used for real-world simulation.
Most existing solutions to these challenges are data-driven, by using large multimodal T2V datasets that cover different real-world domain. However, these solutions heavily rely on the volume, quality and diversity of datasets. Since real-world common knowledge and physical rules are not explicitly embedded in the T2V generation process, as shown in the figure below, the quality of video generation would largely drop in out-of-distribution domains that are not covered by the training dataset, and the generalizability of T2V models is limited due to the vast diversity of real-world scenario domains.

To achieve generalizable enforcement of physics-grounded T2V generation, we propose a fundamentally different approach: instead of expanding the training dataset or further complicating the T2V model architecture, we aim to expand the current T2V model’s capability of video generation from in-distribution to out-of-distribution domains, by embedding real-world knowledge and physical rules into the text prompts with sufficient and appropriate contexts. To avoid ambiguous and unexplainable prompt engineering, our basic idea is to enable chain-of-thought (CoT) and step-back reasoning in T2V generation prompting, to ensure that T2V models follow correct physical dynamics and inter-frame consistency by applying step-by-step guidance and iterative refinement.
Our Approach
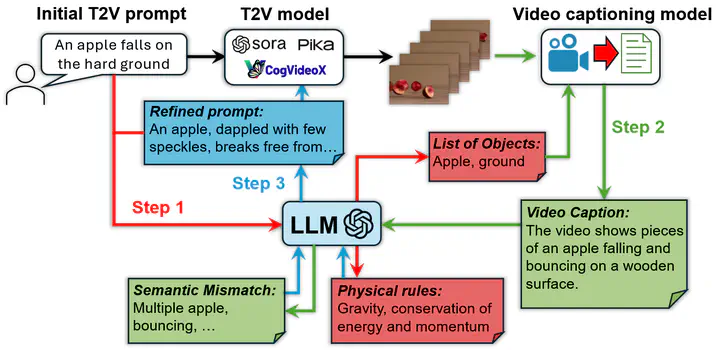
As shown in the figure below, reasoning is iteratively conducted in PhyT2V, and each iteration autonomously refines both the T2V prompt and generated video in three steps.
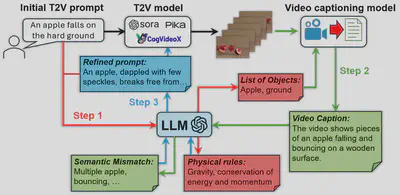
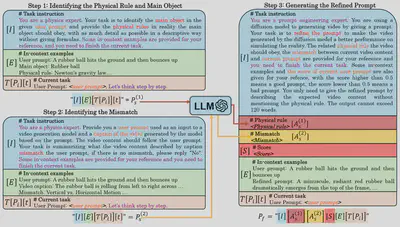
In Step 1, the LLM analyzes the T2V prompt to extract objects to be shown and physical rules to follow in the video via in-context learning. In Step 2, we first use a video captioning model to translate the video’s semantic contents into texts according to the list of objects obtained in Step 1, and then use the LLM to evaluate the mismatch between the video caption and current T2V prompt via CoT reasoning. In Step 3, the LLM refines the current T2V prompt, by incorporating the physical rules summarized in Step 1 and resolving the mismatch derived in Step 2, through step-back prompting. The refined T2V prompt is then used by the T2V model again for video generation, starting a new round of refinement. Such iterative refinement stops when the quality of generated video is satisfactory or the improvement of video quality converges. You may find an example of our prompt design for the 3 steps in the figure below.
Result Showcase
The images below show a comparison between videos generated by the current text-to-video generation model (CogVideoX-5B) that cannot adhere to the real-world physical rules (described in brackets following the user prompt, and our method PhyT2V, when applied to the same model, better reflects the real-world physical knowledge.

Online Demo
We have released a Discord Bot which allows you to try our work on-the-fly with SOTA T2V models. Please visit this link to get started.
