FreezeAsGuard: Mitigating Illegal Adaptation of Diffusion Models via Selective Tensor Freezing
Abstract
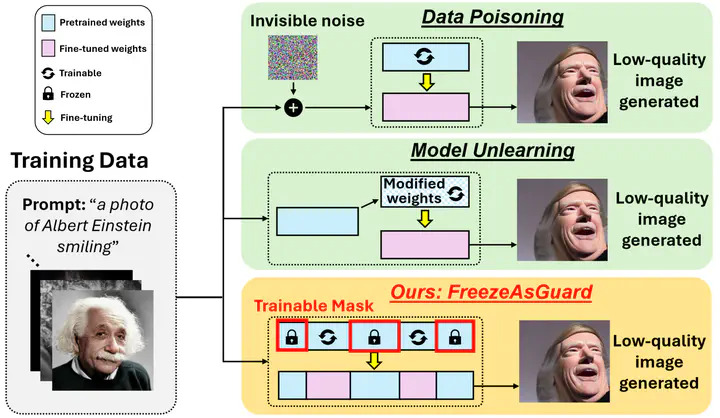
Text-to-image diffusion models can be fine-tuned in custom domains to adapt to specific user preferences, but such adaptability has also been utilized for illegal purposes, such as forging public figures’ portraits, duplicating copyrighted artworks and generating explicit contents. Existing work focused on detecting the illegally generated contents, but cannot prevent or mitigate illegal adaptations of diffusion models. Other schemes of model unlearning and reinitialization, similarly, cannot prevent users from relearning the knowledge of illegal model adaptation with custom data. In this paper, we present FreezeAsGuard, a new technique that addresses these limitations and enables irreversible mitigation of illegal adaptations of diffusion models. Our approach is that the model publisher selectively freezes tensors in pre-trained diffusion models that are critical to illegal model adaptations, to mitigate the fine-tuned model’s representation power in illegal adaptations, but minimize the impact on other legal adaptations. Experiment results in multiple text-to-image application domains show that FreezeAsGuard provides 37% stronger power in mitigating illegal model adaptations compared to competitive baselines, while incurring less than 5% impact on legal model adaptations.
Overview
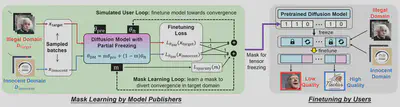
Our design of FreezeAsGuard builds on bilevel optimization, which embeds one optimization problem within another. As shown in the figure below, the lower-level optimization problem is a simulated user loop that the user fine-tunes the diffusion model towards convergence by minimizing the loss over both illegal and innocent domains. The upper-level problem is a mask learning loop that the model publisher learns m to mitigate the diffusion model’s representation power when being fine-tuned in illegal domains, without affecting fine-tuning in innocent domains.
Qualitative Examples of Generated Images
In our experiments, we use three open-source diffusion models, SD v1.4, v1.5 and v2.1, to evaluate three domains of illegal model adaptations:
Forging Public Figures’ Portraits
We use a self-collected dataset, namely Famous-Figures-25 (FF25),
with 8,703 publicly available portraits of 25 public figures on the Web.
Each image has a prompt “a photo of <person_name> showing
The following figures show qualitative examples of generated images in illegal domains of 10 subjects in our FF25 dataset, after applying FreezeAsGuard-30% to fine-tuning SD v1.5. Each prompt adopts the same seed for generation.


Duplicating copyrighted Artworks
We use a self-collected dataset, namely Artwork, which contains 1134 publicly available artwork images and text captions on the Web, from five famous digital artists with unique art styles.
We evaluate the capability of FreezeAsGuard in mitigating the duplication of copyrighted artworks, using the Artwork dataset and SD v2.1 model. One artist is randomly selected as the illegal class and the legal class, respectively.

Generating Explicit Content
We use the NSFW-caption dataset with 2,000 not-safe-for-work (NSFW) images and their captions as the illegal class. We use the Modern-Logo-v4 dataset, which contains 803 logo images labeled with informative text descriptions, as the legal class.

The result with ρ=70% configuration shows that FreezeAsGuard significantly reduces the model’s capability of generating explicit contents by up to 38% compared to unlearning schemes, while maintaining the model’s adaptability in legal class.
