Tackling Intertwined Data and Device Heterogeneities in Federated Learning with Unlimited Staleness
Abstract
Federated Learning (FL) can be affected by data and device heterogeneities, caused by clients’ different local data distributions and latencies in uploading model updates (i.e., staleness). Traditional schemes consider these heterogeneities as two separate and independent aspects, but this assumption is unrealistic in practical FL scenarios where these heterogeneities are intertwined. In these cases, traditional FL schemes are ineffective, and a better approach is to convert a stale model update into a unstale one. In this paper, we present a new FL framework that ensures the accuracy and computational efficiency of this conversion, hence effectively tackling the intertwined heterogeneities that may cause unlimited staleness in model updates. Our basic idea is to estimate the distributions of clients’ local training data from their uploaded stale model updates, and use these estimations to compute unstale client model updates. In this way, our approach does not require any auxiliary dataset nor the clients’ local models to be fully trained, and does not incur any additional computation or communication overhead at client devices. We compared our approach with the existing FL strategies on mainstream datasets and models, and showed that our approach can improve the trained model accuracy by up to 25% and reduce the number of required training epochs by up to 35%.
Background
An intuitive solution to device heterogeneity in Federated Learning is asynchronous FL, which does not wait for slow clients but updates the global model whenever having received a client update. If a slow client’s excessive latency is longer than a training epoch, it will use an outdated global model to compute its model update, which will be stale when aggregated at the server and affect model accuracy. Traditional asynchronous Federated Learning (AFL) solution to staleness, such as weighted aggregation, results in improper bias towards fast clients and misses important knowledge in slow clients’ model updates, when data and device heterogeneities are intertwined.
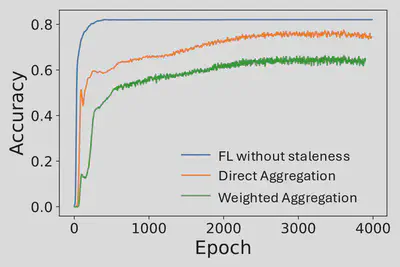
we conducted experiments using a real-world disaster image dataset, which contains 6k images of 5 disaster classes (e.g., fires and floods) with different levels of damage severity. In FL of 100 clients, we set data heterogeneity as that each client only contain samples in one data class, and set device heterogeneity as a staleness of 100 epochs on 15 clients with images of severe damage. When using this dataset to fine- tune a pre-trained ResNet18 model, results in the figure below show that staleness leads to large degradation of model accuracy, and weighted aggregation results in even lower accuracy than direct aggregation, because contributions from images of severe damage on stale clients are reduced by the weights.
Methodology
We propose addressing the above limitations based on existing techniques of gradient inversion. Gradient inversion (GI) aims to recover the original training data from gradients of a model under the white box setting where the all information about the model is known. The basic idea is to minimize the difference between the trained model’s gradient and the gradient computed from the recovered data.
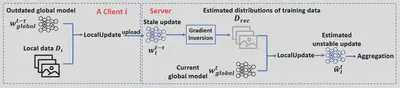
As shown in the figure above, our proposed technique consists of three key components: 1) recovering an intermediate dataset from the received stale model update via gradient inversion to represent the distribution of the client’s training data; 2) estimating the unstale model update using the recovered dataset; and 3) deciding when to switch back to vanilla FL in the late stage of FL training, to avoid the excessive estimation error from gradient inversion.
Experiment Results
We evaluated our proposed technique in two FL scenarios. In the first scenario, all clients’ local datasets are fixed. In the second scenario, we consider a more practical FL setting, where clients’ local data is continuously updated and data distributions are variant over time. In all experiments, we consider a FL scenario with 100 clients. We assess our approach’s performance improvement by measuring the increase of model accuracy in the selected data class being affected by staleness.
FL Performance in the Fixed Data Scenario
In the fixed data scenario, 3 standard datasets and 1 domain-specific dataset are used in evaluations, including MNIST, FMNIST, CIFAR-10 and a disaster image dataset MDI:
- Using MNIST and FMNIST datasets to train a LeNet model, and data class 5 is affected by staleness.
- Using CIFAR-10 dataset to train a ResNet-18 model, data class 2 is affected by staleness.
- Using a disaster image dataset MDI to fine-tune the ResNet-18 model pre-trained with ImageNet.
The trained model’s accuracies using different FL schemes, with the amount of staleness as 40 epochs, are listed in the table below.
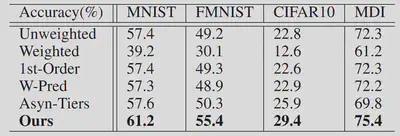
Results show that our gradient inversion based compensation can improve the trained model’s accuracy by at least 4%, compared to the best baseline. Such advantage in model accuracy can be as large as 25% when compared with Weighted aggregation.
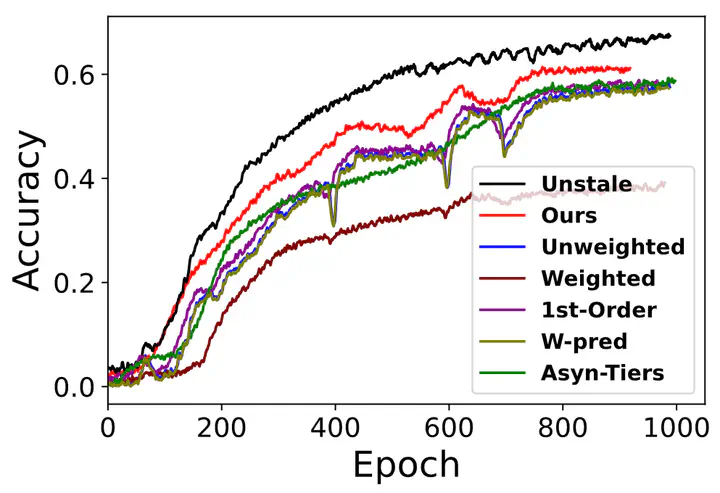
The figure below showing the training procedure comparisondemonstrated that our method can also improve the progress and stability of training while also achieve higher model accuracy during different stages of FL training.
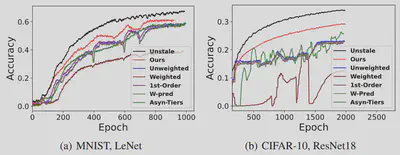
FL Performance in the Variant Data Scenario
To verify performance with continuously varied data distributions of clients’ local datasets, we use MNIST and SVHN datasets, which are for the same learning task (i.e., handwriting digit recognition) but with different feature representations. Each client’s local dataset is initialized as the MNIST dataset in the same way as in the fixed data scenario. Afterwards, during training, each client continuously replaces random data samples in its local dataset with new data samples in the SVHN dataset.
Results in the figure below show that in such variant data scenario, the model accuracy improvements by the existing FL training strategies exhibit significant fluctuations over time and stay low (<40%). in comparison, our proposed gradient inversion based estimation achieves much higher model accuracy, which is comparable to FL without staleness and 20% higher than those in existing FL schemes.
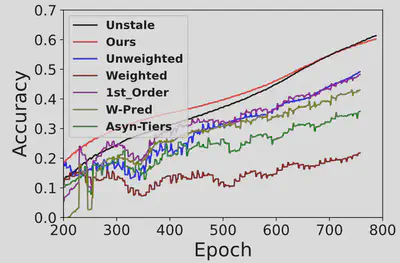
More results below with different amounts of staleness and rates of data variation (streaming rate) also demonstrate that our proposed method outperformed the existing FL strategies in different scenarios with different dynamics of local data patterns.

