Towards Green AI in Fine-tuning Large Language Models via Adaptive Backpropagation

Abstract
Fine-tuning is the most effective way of adapting pre-trained large language models (LLMs) to downstream applications. With the fast growth of LLM-enabled AI applications and democratization of open-souced LLMs, fine-tuning has become possible for non-expert individuals, but intensively performed LLM fine-tuning worldwide could result in significantly high energy consumption and carbon footprint, which may bring large environmental impact. Mitigating such environmental impact towards Green AI directly correlates to reducing the FLOPs of fine-tuning, but existing techniques on efficient LLM fine-tuning can only achieve limited reduction of such FLOPs, due to their ignorance of the backpropagation cost in fine-tuning. To address this limitation, in this paper we present GreenTrainer, a new LLM fine-tuning technique that adaptively evaluates different tensors’ backpropagation costs and contributions to the fine-tuned model accuracy, to minimize the fine-tuning cost by selecting the most appropriate set of tensors in training. Such selection in GreenTrainer is made based on a given objective of FLOPs reduction, which can flexibly adapt to the carbon footprint in energy supply and the need in Green AI. Experiment results over multiple open-sourced LLM models and abstractive summarization datasets show that, compared to fine-tuning the whole LLM model, GreenTrainer can save up to 64% FLOPs in fine-tuning without any noticeable model accuracy loss. Compared to the existing fine-tuning techniques such as LoRa, GreenTrainer can achieve up to 4% improvement on model accuracy with on-par FLOPs reduction.
Presentation Video
Alternatively, you may also find the presentation video recording here (please use Google Chrome browser to visit if error occurs).
The Need for Adaptive Backpropagation
Fine-tuning with fixed selections of NN components in inefficient. It either significantly impairs the trained model’s accuracy or brings limited FLOPs saving. The deficiency of these existing methods motivates us to enforce more flexible and adaptive selection of LLM substructures in backpropagation.
In GreenTrainer, we develop a tensor importance metric that incorporates parameter dependencies to evaluate how fine-tuning each tensor contributes to the trained model’s accuracy at runtime. Knowledge about such tensor importance, then, allows us to achieve the desired FLOPS reduction while maximizing the model accuracy.

FLOPs Model of Backpropagation
The design of GreenTrainer relies on proper calculation of the selected model substructures’ backpropagation FLOPs, which can be decomposed into two parts using the chain rule. For example, when training a 4-layer dense NN without bias, each layer computes i) $dy_i$ as the loss L’s gradient w.r.t the activation $y_i$, and ii) $dw_i$ as the loss gradient w.r.t weight $W_i$. Based on this rationale, we can construct FLOPs models for LLM substructures, including MHA and FFN.
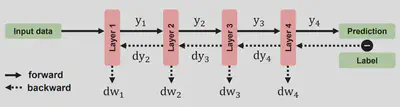
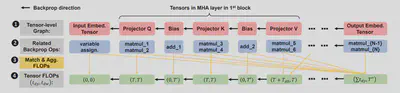
Tensor FLOPs Profiling
GreenTrainer constructs the LLMs FLOPs model by profiling tensor FLOPs. First, we convert the layer-based NN structure of LLMs into a tensor-level computing graph, which retains the execution order of all tensors’ involvements in training. Then, we extract the related backpropagation operators of each tensor, and derive each tensor $i$’s FLOPs in backpropagation ($t_{dy_i}$ and $t_{dw_i}$) by matching and aggregating the FLOPs of these NN operators.
Experimental Results
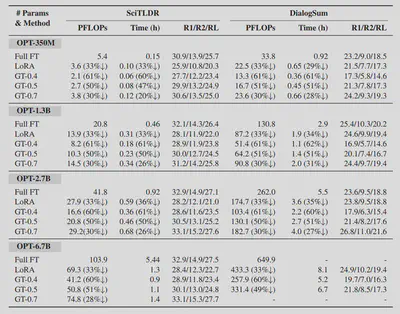
We evaluated the training performance of GreenTrainer with three open-sourced LLMs, namely OPT, BLOOMZ and FLAN-T5, on text generation datasets including SciTLDR and DialogSum. We compare GreenTrainer’s performance with existing efficient fine-tuning techniques such as Prefix Tuning and LoRA.
Our experiment results show that GreenTrainer can save up to 64% training FLOPs compared to full LLM fine-tuning, without any noticeable accuracy loss. Compared to existing fine-tuning techniques such as Prefix Tuning and LoRA, GreenTrainer can improve the model accuracy by 4%, with the same amount of FLOPs reduction!
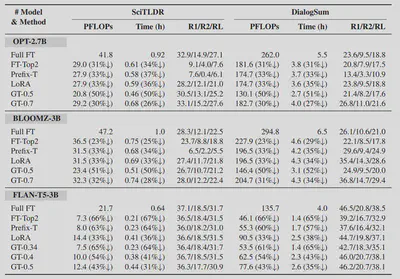
GreenTrainer provides users with the flexibility to balance between the training accuracy and cost depending on the specific needs of green AI!
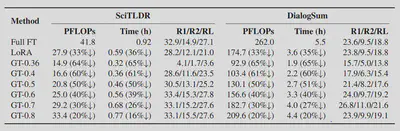
GreenTrainer maintains good performance on fine-tuning LLMs with different sizes!