Real-time Neural Network Inference on Extremely Weak Devices: Agile Offloading with Explainable AI

Abstract
With the wide adoption of AI applications, there is a pressing need of enabling real-time neural network (NN) inference on small embedded devices, but deploying NNs and achieving high performance of NN inference on these small devices is challenging due to their extremely weak capabilities. Although NN partitioning and offloading can contribute to such deployment, they are incapable of minimizing the local costs at embedded devices. Instead, we suggest to address this challenge via agile NN offloading, which migrates the required computations in NN offloading from online inference to offline learning. In this paper, we present AgileNN, a new NN offloading technique that achieves real-time NN inference on weak embedded devices by leveraging eXplainable AI techniques, so as to explicitly enforce feature sparsity during the training phase and minimize the online computation and communication costs. Experiment results show that AgileNN’s inference latency is >6X lower than the existing schemes, ensuring that sensory data on embedded devices can be timely consumed. It also reduces the local device’s resource consumption by >8X, without impairing the inference accuracy.
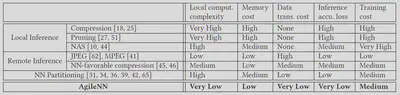
AgileNN vs. Existing Work
AgileNN is a new technique that shifts the rationale of NN partitioning and offloading from fixed to agile and data-centric. Our basic idea is to incorporate the knowledge about different input data’s heterogeneity in training, so that the required computations to enforce feature sparsity are migrated from online inference to offline training.
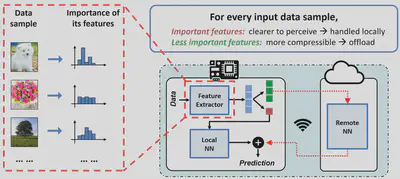
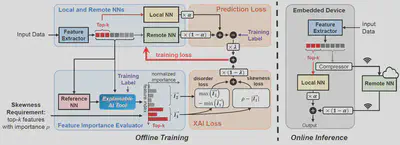
System Overview
AgileNN partitions the neural network into a Local NN and a Remote NN. In online inference, AgileNN runtime uses a lightweight feature extractor at the local embedded device to provide feature inputs: the top-k features with high importance are retained by the Local NN to make a local prediction, which is then combined with the Remote NN’s prediction from other less important features for the final inference output. In this way, the complexity of Local NN could be minimized without impairing the inference accuracy, and high sparsity can be enforced when compressing and transmitting less important features to the server.
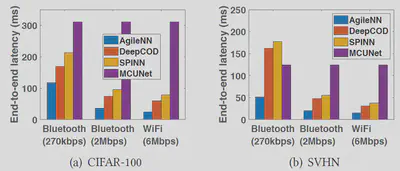
Experimental Results
We implemented our offline training procedure using tensorflow and deployed the trained local NN and remote NN on a weak microcontroller board and a Dell workstation, respectively. The microcontroller board is equipped with an ESP WiFi module for wireless data transmission. We focus on image recognition tasks and use CIFAR, SVHN and a subset of ImageNet as the datasets in evaluation.
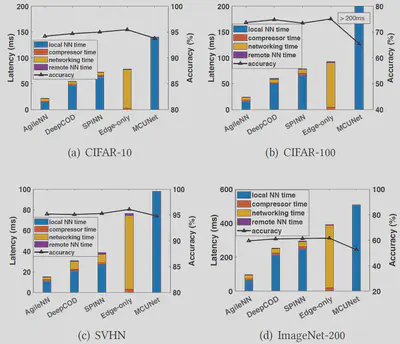
AgileNN reduces end-to-end latency by 2x-2.5x! compared to existing schemes!
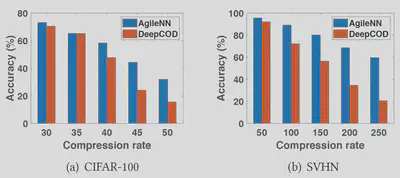
AgileNN maintains better accuracy under extreme compression rates!
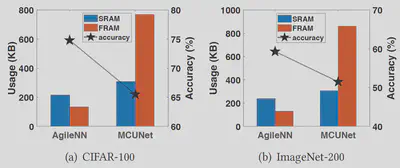
AgileNN consumes less local memory and storage!
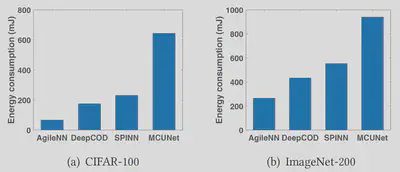
AgileNN consumes less local energy!
AgileNN can maintain the best performance under different wireless bandwidths!