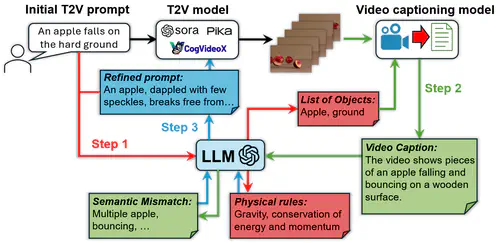
Text-to-video (T2V) generative AI could revolutionize many current and emerging application and industry domains. However, the capabilities of today’s T2V generative models are mostly data dependent. While they perform well in domains covered by the training data, they usually fail to obey the real-world common knowledge and physical rules with out-of-distribution prompts. Expanding the model’s capabilities, on the other hand, relies on large amounts of real-world data and is hence not scalable. Our recent work aims to address this limitation of data dependency, by fully unleashing the current T2V models’ potential in scene generation given proper and detailed prompts. Our approach, namely PhyT2V, is a training-free technique that leverages the LLM’s capabilities of chain-of-thought and step-back reasoning in the language domain, to logically identify the deficiency of generated videos and iteratively refine the current T2V models’ video generation by correcting such deficiency with more precise and well articulated prompts.