Published Dataset
InfiniBench
December 2025
InfiniBench is a dataset generator for procedurally generated 3D indoor environments designed for multimodal AI, embodied agents, and spatial reasoning tasks.
These scenes were created using an enhanced version of Infinigen that utilizes Agentic Constraint Generation (LLM-driven scene descriptions and code refinement) and Cluster-Based Layout Optimization to create logical, rigid-body furniture arrangements.
Each entry in this dataset represents a unique scene containing the raw 3D assets (.blend), optimized camera navigation trajectories (frontier-based exploration), rendered video feeds, and rich metadata for Visual Question Answering (VQA).
Data Structure
The dataset is organized by Scene ID. Each folder contains the assets, intermediate navigation results, renders, and metadata for a single generated environment.
Folder Layout
dataset_root/
├── scene_ID/
│ ├── scene.blend # Full 3D environment (Blender)
│ ├── trajectory/
│ │ ├── trajectory_data.csv # Position & Rotation (Euler) for every frame
│ │ └── segmentation_maps/ # 2D Segmentation masks corresponding to the path
│ ├── render/
│ │ ├── frames/ # Individual rendered frames
│ │ └── trajectory_video.mp4 # Compiled video of the optimized path
│ └── metadata/
│ ├── object_bbox_dimensions.csv # 3D Bounding box sizes for all objects
│ ├── object_appearance.csv # Order of appearance in the video
External Resources
- Visit InfiniBench dataset on HuggingFace for detailed description and dataset downloading.
- Visit InfiniBench repository on GitHub for related source code.
- Check out our paper about this dataset.
ReMindView-Bench
December 2025
ReMindView-Bench is a cognitively grounded benchmark for evaluating how Vision-Language Models (VLMs) construct, align, and maintain spatial mental models across complementary viewpoints. It addresses the struggle of current VLMs to maintain geometric coherence and cross-view consistency for spatial reasoning in multi-view settings by providing a fine-grained benchmark that isolates multi-view reasoning.
Dataset Content
The dataset mainly consists of VQA samples. The metadata are stored in CSV files with the following columns: folder_path (scene/view folder), query_type (query relationship type), query, ground_truth, choices, cross_frame (whether cross frame reasoning is necessary), perspective_changing (whether requiring perspective changing), and object_num (object number in all frames).
An example row looks like this:
folder_path:dense_view_centric_view_frame_outputs_processed/Bedroom/Bedroom_1/MattressFactory(7143095).spawn_asset(3158442)/level_20query_type:object-object|relative_distance|non_perspective_changing|0query:“Which object is the closest to the shell?”choices:A.pillow, B.toy animal, C.shellground_truth:B.toy animalcross_frame:Trueperspective_changing:Falseobject_num:18
Sample Scene
Below you can find a data sample render showing indoor layouts and object detail captured in the benchmark.
- Query: If you are positioned where the white sofa is, facing the same direction of the white sofa, what is the spatial relationship of the white TV stand to shelf trinket?
- Choice: A. front-right, B. left, C. back, D. back-right
- Answer: B. left
External Resources
- Visit ReMindView-Bench dataset on HuggingFace for detailed description and dataset downloading.
- Visit ReMindView-Bench repository on GitHub for related source code.
- Check out our paper about this dataset.
ProGait
July 2025
ProGait is a multi-purpose video dataset aimed to support multiple vision tasks on prosthesis users, including Video Object Segmentation, 2D Human Pose Estimation, and Gait Analysis. ProGait provides 412 video clips from four above-knee amputees when testing multiple newly-fitted prosthetic legs through walking trials, and depicts the presence, contours, poses, and gait patterns of human subjects with transfemoral prosthetic legs.
Example data sample and annotations:
- Visit ProGait dataset on HuggingFace for detailed description and dataset downloading.
- Visit ProGait repository on GitHub for related source code.
- Our ProGait paper makes use of this dataset.
Famous-Figures-25 (FF25)
June 2024
Our FF25 dataset contains 8,703 portrait images of 25 public figures and the corresponding text descriptions. All the images were crawled from publicly available sources on the Web. These 25 subjects include politicians, movie stars, writers, athletes and businessmen, with diverse genders, races, and career domains. As shown in Figure 11, the dataset contains 400-1,300 images of each subject.

Each raw image is then center-cropped to a resolution of 512×512. For each image, we use a pre-trained BLIP2 image captioning model to generate the corresponding text description, and prompt BLIP2 with the input of “a photo of <person_name> which shows” to avoid hallucination.
The file structure is as follows:
test/<person_name>/img_<img_number>.pngtest/metadata.csvtrain/<person_name>/img_<img_number>.pngtrain/metadata.csv
For details, please refer to our related source code repository and paper.
- You may download the dataset from our dataset homepage.
- The source code related to using the dataset can be found from our GitHub repository.
- Our FreezeAsGuard paper makes use of the FF25 dataset.
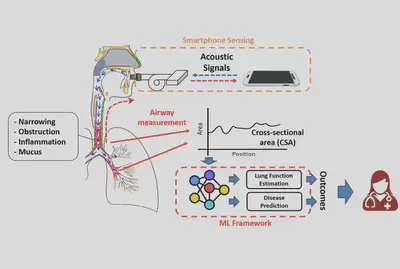
Acoustic Waveform Respiratory Evaluation (AWARE)
January 2024
The Acoustic Waveform Respiratory Evaluation (AWARE) dataset consists of a group of human airway measurements, produced by our integrated AI and sensing systems for smart pulmonary telemedicine.
This dataset contains airway measurements of 382 human subjects, including patients with various pulmonary diseases and healthy control subjects, recruited from the Children’s Hospital of Pittsburgh during the past 3 years. The contents of the dataset include raw WAV files from acoustic sensing, segmented and aligned acoustic signal pulses, and processed measurements of airway cross-sectional areas.
- Visit AWARE dataset homepage for more information.
- The source code related to using the dataset can be found from our GitHub repository.
- Our PTEase paper makes use of the AWARE dataset.
To our best knowledge, this is the first public dataset of human airway measurements with pulmonary diseases, and we welcome any feedback from the smart health research community.
NuScenes-QA-mini Dataset
January 2024
This dataset is used for multimodal question-answering tasks in autonomous driving scenarios. We created this dataset based on nuScenes-QA dataset for evaluation in our paper Modality Plug-and-Play: Elastic Modality Adaptation in Multimodal LLMs for Embodied AI. The dataset is stored on HuggingFace.
Detailed Description
This dataset is built on the nuScenes mini-split, where we obtain the QA pairs from the original nuScenes-QA dataset. Each data sample contains 6-view RGB camera captures, a 5D LiDAR point cloud, and a corresponding text QA pair. The data in the nuScenes-QA dataset is collected from driving scenes in cities of Boston and Singapore with diverse locations, time, and weather conditions.
Dataset Components
The samples are divided into day and night scenes:
| Scene | # train samples | # validation samples |
|---|---|---|
| day | 2,229 | 2,229 |
| night | 659 | 659 |
Each sample contains:
- Original token id in nuscenes database.
- RGB images from 6 views (front, front left, front right, back, back left, back right).
- 5D LiDAR point cloud (distance, intensity, X, Y, and Z axes).
- Question-answer pairs.
In this dataset, the questions are generally difficult, and may require multiple hops of reasoning over the RGB and LiDAR data. For example, to answer the sample question in the above figure, the ML model needs to first identify in which direction the “construction vehicle” appears, and then counts the number of “parked trucks” in that direction. In our evaluations, we further cast the question-answering (QA) as an open-ended text generation task. This is more challenging than the evaluation setup in the original nuScenes-QA paper, where an answer set is predefined and the QA task is a classification task over this predefined answer set.
In most RGB images in the nuScenes dataset, as shown in the above figure - Left, the lighting conditions in night scenes are still abundant (e.g., with street lights), and we hence further reduce the brightness of RGB captures in night scenes by 80% and apply Gaussian blur with a radius of 7, as shown in the above figure - Right. By applying such preprocessing to the RGB views in night scenes, we obtain the training and validation splits of night scenes with 659 samples for each split. On the other hand, the RGB views in daytime scenes remain as the origin. The day split contains 2,229 for training and 2,229 for validation respectively.
How to use
With internet connection, you may load this dataset directly using HuggingFace Datasets library:
from datasets import load_dataset
# load train split in day scene
day_train = load_dataset("KevinNotSmile/nuscenes-qa-mini", "day", split="train")
External Resources
- You may find more details on our dataset homepage.
- The source code of generating the dataset can be found in our GitHub repository.
- Our Modality Plug-and-Play paper utilizes this dataset.
Android GPU Performance Counter to Key Press Dataset
December 2023
This dataset comes from our mobile GPU-based eavesdropping work, Eavesdropping user credentials via GPU side channels on smartphones, presented at the 27th ACM International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS 2022). It contains 3,466 traces of mapping between the on-screen keyboard key presses and corresponding Snapdragon Adreno GPU performance counter changes collected on device in the meantime.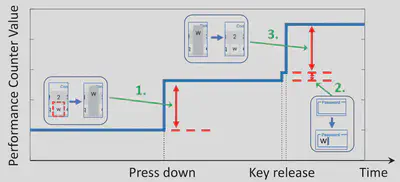
Dataset Structure
The dataset is arranged in the following format:
- Folder name (e.g.,
1622457056): This UNIX timestamp when the experiment took place.timestamp_data.csv: Raw recording of GPU performance counter changes during the experiment.- Column 1: UNIX timestamp of each performance counter value change event, with granularity of 1 microseconds.
- Column 2-13: GPU PC value changes of different types:
PERF_LRZ_VISIBLE_PRIM_AFTER_LRZPERF_LRZ_FULL_8X8_TILESPERF_LRZ_PARTIAL_8X8_TILESPERF_LRZ_VISIBLE_PIXEL_AFTER_LRZPERF_RAS_SUPERTILE_ACTIVE_CYCLESPERF_RAS_SUPER_TILESPERF_RAS_8X4_TILESPERF_RAS_FULLY_COVERED_8X4_TILESPERF_VPC_PC_PRIMITIVESPERF_VPC_SP_COMPONENTSPERF_VPC_LRZ_ASSIGN_PRIMITIVESPERF_VPC_SP_LM_COMPONENTS
timestamp_keys.csv: Keyboard key presses occurred during the experiment.- Column 1: UNIX timestamp of each key press, with granularity of 1 microseconds.
- Column 2: The specific key press occurred.
For the discussion of detailed meanings of different GPU PCs, please refer to Section 4 of our paper.
External Resources
- You may find more details on our dataset homepage.
- Our Mobile GPU Eavesdropping paper provides more information on the background and information leakage based on GPU PCs.
