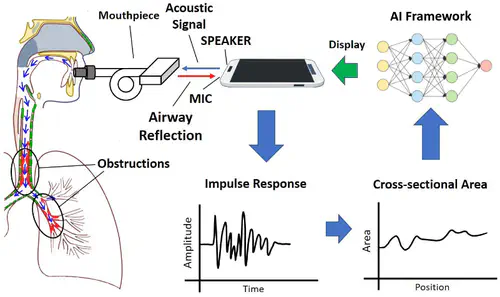
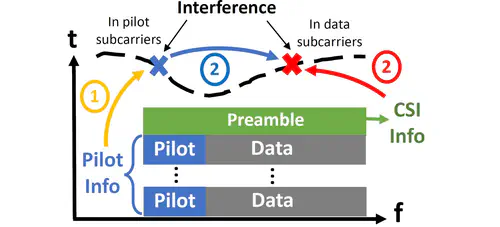
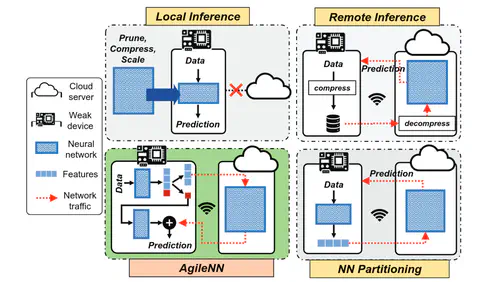
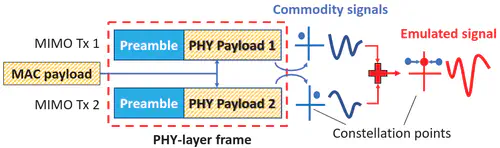
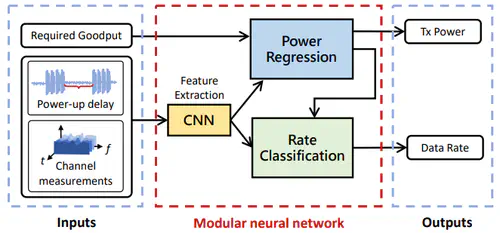
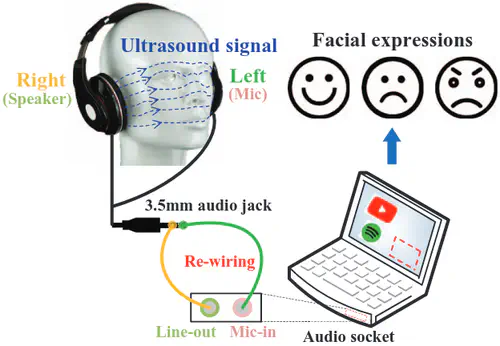
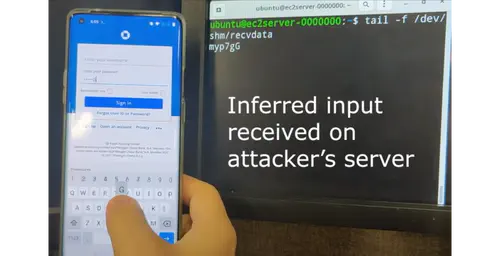
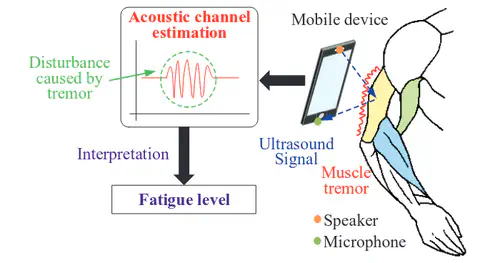
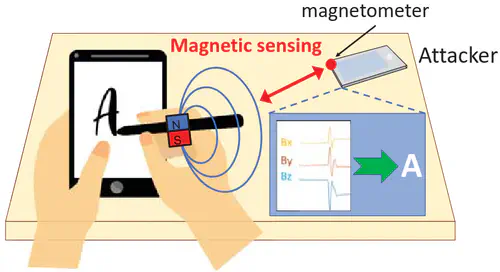
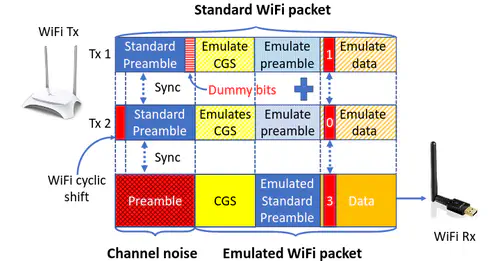
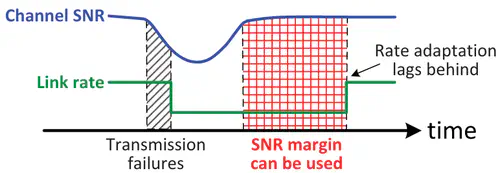
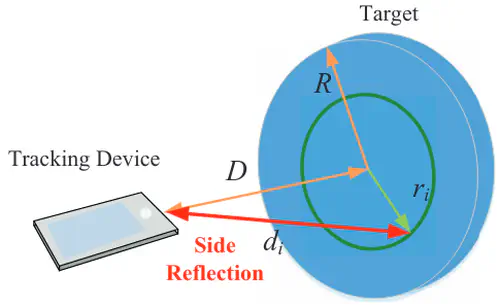
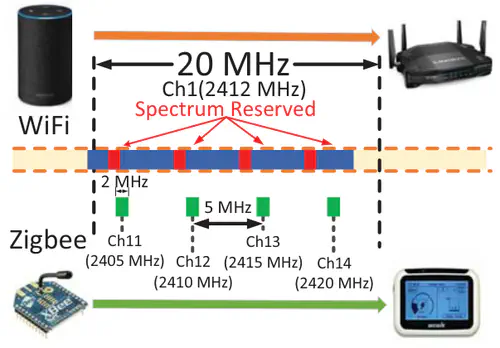
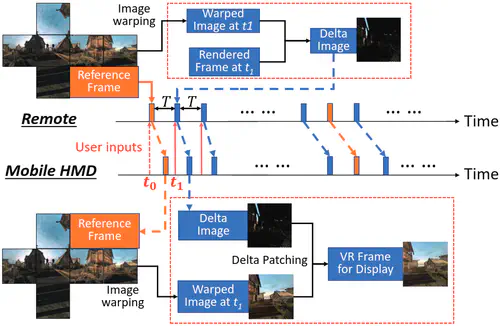
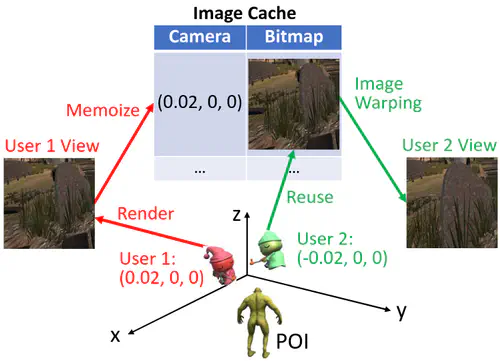
This is the first work that allows multimodal LLMs to elastically switch between input data modalities at runtime, for embodied AI applications such as autonomous navigation. Our basic technical approach is to use fully trainable projectors to adaptively connect the unimodal data encoders being used to a flexible set of last LLM blocks. In this way, we can flexibly adjust the amount of LLM blocks being connected to balance between accuracy of runtime fine-tuning cost, and optimize the efficiency of cross-modal interaction by controlling the amount of information being injected in each connection. Our implementations on NVidia Jetson AGX Orin demonstrate short modality adaptation delays of few minutes with mainstream LLMs, 3.7x fine-tuning FLOPs reduction, and 4% accuracy improvements on multimodal QA tasks.